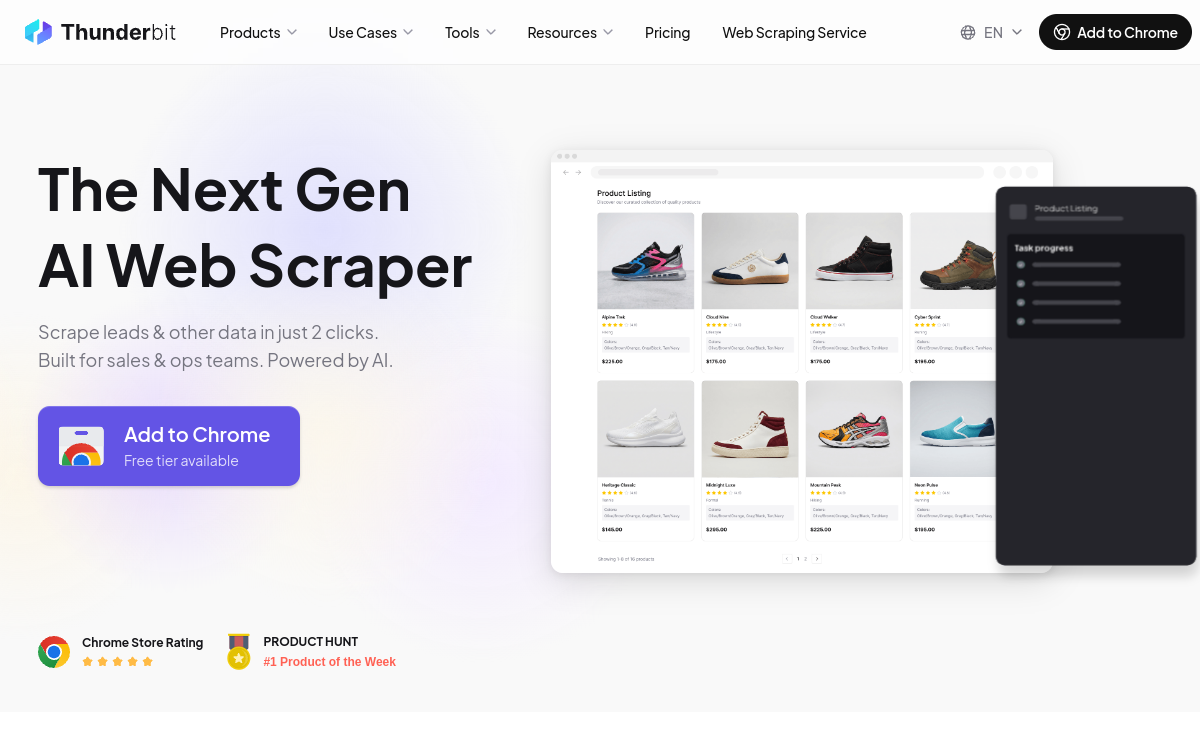
Thunderbit è un’__estensione Chrome senza codice__ alimentata dall’IA (ChatGPT, Claude, Gemini) che consente di estrarre dati da qualsiasi sito web in due clic. L’utente descrive semplicemente le colonne desiderate in linguaggio naturale, e Thunderbit configura automaticamente lo scraper. Supporta lo __scraping di sotto-pagine__, l’estrazione da __PDF e immagini__, ed esporta gratuitamente verso Excel, Google Sheets, Airtable e Notion. Accessibile ai __non-sviluppatori__, è lo strumento ideale per i team di marketing, commerciali e operativi che desiderano automatizzare la loro __raccolta di dati web__.
Che cos’è Thunderbit?
Thunderbit è un’estensione Chrome di web scraping senza codice pilotata dall’intelligenza artificiale. L’utente visita una pagina, descrive le colonne che desidera estrarre in linguaggio naturale, e Thunderbit analizza la struttura della pagina per configurare automaticamente lo scraper. L’IA identifica i dati pertinenti, li estrae e li presenta in una tabella strutturata pronta per l’esportazione. Lo strumento supporta non solo lo scraping di pagine web standard, ma anche lo scraping di sotto-pagine (seguendo i link), l’estrazione da PDF — anche scansionati — e da immagini.
Funzionalità principali
Thunderbit si basa su un motore IA multi-modello che combina ChatGPT, Gemini e Claude per interpretare le istruzioni in linguaggio naturale e analizzare la struttura delle pagine. Tra le sue funzionalità principali: lo scraping di sotto-pagine che segue automaticamente i link per compilare un dataset consolidato, lo scraping di lotti di URL per elaborare centinaia di pagine in una sola operazione, la pianificazione di scraper ricorrenti fino a una frequenza di 5 minuti, e un arricchimento dati integrato. L’esportazione è gratuita verso Excel, Google Sheets, Airtable e Notion. Gli estrattori specializzati per email, numeri di telefono e immagini sono disponibili gratuitamente su tutti i piani.
Casi d’uso
Thunderbit è particolarmente utile per i team commerciali che estraggono lead da LinkedIn, directory e siti settoriali. I marketer lo utilizzano per monitorare i prezzi dei concorrenti, raccogliere recensioni di clienti o aggregare contenuti per il monitoraggio. Gli analisti senza competenze di programmazione lo utilizzano per alimentare i dashboard. I team HR possono estrarre offerte di lavoro per studi di mercato, e i ricercatori utilizzano lo strumento per costituire corpus di dati da fonti web pubbliche.
Vantaggi
Il principale vantaggio di Thunderbit è l’accessibilità: non sono richieste competenze tecniche per iniziare. La configurazione di uno scraper richiede meno di due minuti rispetto a diverse ore con strumenti classici. L’esportazione verso gli strumenti esistenti (Sheets, Notion, Airtable) senza costi aggiuntivi riduce gli attriti di integrazione. La combinazione di più modelli IA migliora la precisione dell’estrazione su pagine complesse.
Tariffe
Thunderbit offre un piano gratuito con 6 pagine al mese (30 crediti per pagina). Il piano Starter è disponibile a 9$/mese fatturato annualmente, includendo 5.000 crediti all’anno, lo scraping di sotto-pagine e la pianificazione di base. Il piano Pro a 16,50$/mese (annuale) offre 30.000 crediti, la conservazione illimitata dei dati e 25 scraper pianificati. Un piano Business con crediti personalizzati e supporto prioritario è disponibile anche per i grandi team.
Conclusione
Thunderbit occupa una nicchia precisa e la riempie con brio: rendere lo web scraping accessibile ai non-sviluppatori grazie all’IA. Per i team che hanno bisogno di raccogliere dati web senza investire nello sviluppo, è una soluzione efficace, conveniente e facile da padroneggiare. I suoi limiti (nessuna API, volumi moderati) sono accettabili per il suo pubblico target.